This post aims to cover the basic knowledge on
Component Cohesion/Coupling Digraphs(
Com Coh/Cou Digraph, same below). Subsequent replies will demonstrate some practical applications in some plugins.
You're assumed to have a basic knowledge on:
1.
Block diagram2.
Cohesion3.
Coupling4.
DigraphsComponent DiagramLayered Approach[spoiler]
Let's start with the below easy, simple and small block diagram showing the high level of a system:
[spoiler]
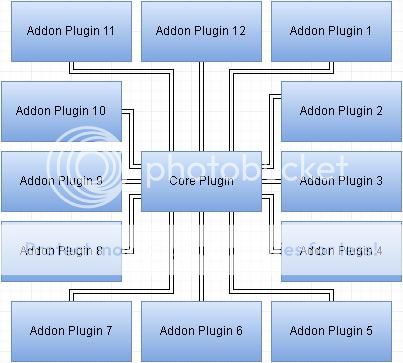
If we want to know the details of a plugin of a system, we can also use a block diagram for each plugin, which can be something like this:
If each feature's considered as a component, then this plugin's said to have 12 components(you may want to have a basic knowledge on
interface in case you don't).
So as we go from a higher layer to a lower layer, more and more details of a component will be shown, but less and less information about how that component interact with the entire system as a whole will be revealed as well.[/spoiler]
Showing Number Of ComponentsAs mentioned, a system can have a number of plugins, a plugin can have a number of features, and a feature can have a number of building blocks. What levels of the details will be shown on a graph depends on the layer we're focusing on.
Sometimes though, the number of components within a system/plugin/feature can also be useful, like indicating whether a component's doing too much or too little.
Showcasing the number of components in a block diagram can be as simple as this:
[spoiler]
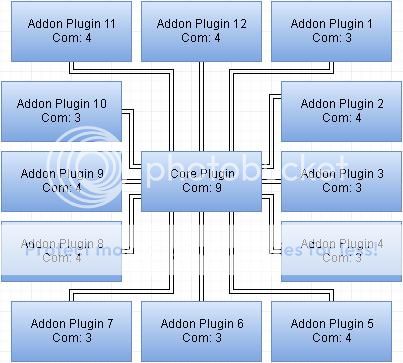
Here Com: x indicates the number of components within a plugin. In this case, it's the number of features within a plugin.
So the core plugin has 9 features and each addon plugin has 3 - 4 features. The total number of features of the whole system is 51.
From my experience, knowledge and observation, these are pretty good numbers, because it's normal for the core plugin to do a lot more than each addon plugin, and no plugin's doing too much or too little.
Note that a block diagram on a layer only shows the number of components on 1 lower layer for each component on this layer. It's because of the Law of Demeter.In short, this approach ensures the overview shown by a high level block diagram won't be obscured by the details from lower levels, except the one just lower than the current level.In this case, Com only shows the number of feature in each plugin, but not the number of building blocks of each feature in each plugin.
To know the number of building blocks of each feature in each plugin, we can look at the block diagram of that plugin instead.
On a side note: While the number of subcomponents within a component can be an excellent approximation of the size of that component in general, it's never meant to be always accurate nor precise for that sense. It's because sometimes a subcomponent can be exceptionally large or small.
[/spoiler]
[/spoiler]
Cohesion Diagram
Cohesion Rating(Coh Rating, Same Below)
[spoiler]
Let's recap different kinds of cohesion. According to wikipedia, the below are all kinds of cohesions that are ordered by the best to the worst:
1. Functional cohesion
2. Sequential cohesion
3. Communicational cohesion
4. Procedural cohesion
5. Temporal cohesion
6. Logical cohesion
7. Coincidental cohesion
If we were to use a number as a rating to represent the cohesion level of a component, we can simply use the above numbers - 1 represents functional cohesion, 2 represents sequential cohesion, 3 represents communicational cohesion, ..., 7 represents coincidental cohesion.
That's what's Coh Rating's about. The smaller the number, the higher the cohesion. Note that it's a simplified indicator that gives a quick, rouge and vague impression of how good the cohesion of a component is.
Just like showing the number of components in a block diagram, showing the
Coh Rating in a block diagram can be as simple as this:
[spoiler]

Here Coh: x indicates the
Coh Rating of a plugin.
So the core plugin exhibits sequential cohesion and all addon plugins exhibit functional cohesion. The
Coh Rating Sum of the whole system's 14.
From my experience, knowledge and observation, these are pretty good numbers, because functional cohesion's ideal and sequential cohesion's still acceptable.
Note that a block diagram on a layer only shows the Coh Rating of components on this layer. The reason behind that's basically the same as those of the number of components(Com: x).
In this case, Coh: x of a plugin only indicates the overall
Coh Rating of that plugin, but not that of any feature within that plugin.
On a side note:
The overall Coh Rating of the entire system can be different from that derived from diving its Cohesion Rating Sum(Coh Rating Sum, same below) by its number of components. Nevertheless, these 2 numbers are extremely unlikely to have a huge difference.[/spoiler]
[/spoiler]
Coupling Digraph
Coupling Rating(Cou Rating, Same Below)
[spoiler]
Let's recap different kinds of coupling. According to wikipedia, the below are all kinds of couplings that are ordered by the best to the worst:
0. No coupling
1. Message coupling
2. Data coupling
3. Stamp coupling
4. Control coupling
5. External coupling
6. Common coupling
7. Content coupling
If we were to use a number as a rating to represent the coupling level of between components, we can simply use the above numbers - 1 represents message coupling, 2 represents data coupling, 3 represents stamp coupling, ..., 7 represents content coupling.
That's what's Cou Rating's about. The smaller the number, the looser the coupling. Note that it's a simplified indicator that gives a quick, rouge and vague impression of how good the coupling between components are.
On a side note: Temporal coupling's not included here, as it's rather hard to give a rating for temporal coupling, and the key of temporal coupling's how implicit it's. Making a temporal coupling explicit can be simply done by excellent documentations.
Showing the
Cou Rating between components is a bit more complicated, convoluted and costly when compared to that of the number of components and
Coh Rating, but it should still be easy, simple and small:
[spoiler]

Notice that this time arrows are used instead of merely simple lines, meaning that the block diagram's now a digraph.
If component A and component B are connected by an arrow which is pointing from component A to component B, then component A is said to depend on component B.It's possible that they're connected by 2 arrows instead - 1 pointing from component A to component B and 1 having the opposite direction. In this case, these 2 components depend on each other.Regardless of whether there are just 1 arrow or 2 arrows between these components, they're said to exhibit coupling when they're connected by at least 1 arrows.Conversely, if component A and component B aren't connected by any arrows, they're said to exhibit no coupling.Here Cou: x indicates the
Cou Rating of a plugin.
Note that a Cou Rating always has its corresponding arrow.So the core plugin doesn't depend on any addon plugin while all addon plugins depend on the core plugin, all exhibiting message coupling/data coupling. The
Coupling Rating Sum(
Cou Rating Sum, same below) of the entire system's 18.
From my experience, knowledge and observation, these are pretty good numbers, because message coupling's ideal and data coupling's still acceptable and sometimes necessary.
Note that a block diagram on a layer only shows the Cou Rating between components on this layer. The reason behind that's basically the same as those of the number of components(Com: x) and
Coh Rating(Coh: x).
In this case, Cou: x of a plugin only indicates the overall
Cou Rating between plugins, but not that between features within any plugin or between plugins.
Bear in mind though, sometimes no coupling can be undesirable, as shown by the below block diagram:
Here addon plugin 4 exhibits no coupling to the rest of the system(i.e.:, the
Cou Rating Sum of addon plugin 4 is 0), meaning that the former can function as intended without the latter at all.
In this case, addon plugin 4 doesn't really belong to the system and thus should be a completely separate plugin that can totally stand on its own instead.[/spoiler]
InCou Rating/OutCou RatingFor components depending on each other, the block diagram may look something like this:
[spoiler]

Looking at each addon plugin:
1. For the
InCou Rating of addon plugin 1, it exhibits message coupling from addon plugin 2 and data coupling from addon plugin 3; For the
OutCou Rating of addon plugin 1, it exhibits It exhibits data coupling to core plugin and addon plugin 2, and message coupling to addon plugin 3.
2. For the
InCou Rating of addon plugin 2, it exhibits message coupling from addon plugin 3 and data coupling from addon plugin 1; For
OutCou Rating of addon plugin 2, it exhibits It exhibits data coupling to core plugin and addon plugin 3, and message coupling to addon plugin 1.
3. For the
InCou Rating of addon plugin 3, it exhibits message coupling from addon plugin 1 and data coupling from addon plugin 2; For
OutCou Rating of addon plugin 3, it exhibits It exhibits data coupling to core plugin and addon plugin 1, and message coupling to addon plugin 2.
Note that The
InCou Rating Sum of each addon plugin's 3 and its
OutCou Rating Sum's 5.
In this case, it's somehow undesirable although still barely bearable, as changing any addon plugin can risk changing the rest of the addon plugins.
Ideally, each addon plugin should never interfere any other plugin, and only depend on the core plugin and nothing else.On a side note: The
Cou Rating Sum of the entire system's 15.
In general:
1.
The larger the InCou Rating Sum of a component, the easier and more severely that component will be broken due to changes of any other component it's depending on.2.
The larger the OutCou Rating Sum of a component, the easier and more severely that component will break at least some other components depending on it due to it changes.3.
If a component has large InCou Rating Sum and OutCou Rating Sum, when it becomes broken due to changes of some components it depends on, it can in turn break some components depending on it.[/spoiler]
[/spoiler]
Com Coh/Cou DigraphPutting Everything Altogether[spoiler]
While component diagram, cohesion diagram and coupling digraph are useful on their own, it's still better to combine them all in a single digraph.
That's what Com Coh/Cou Digraph's about.For example, combing all the above component diagram, cohesion diagram and coupling digraph can lead to this
Com Coh/Cou Digraph:
[spoiler]

So a
Com Coh/Cou Digraph can quickly shows the below information of its layer entirely:
1. The number of subcomponents of each component
2. The total number of subcomponents
3. The
Coh Rating of each component
4. The
Coh Rating Sum5. The directed dependencies between components
6. The
InCou Rating of each component
7. The
OutCou Rating of each component
8. The
InCou Rating Sum of each component
9. The
OutCou Rating Sum of each component
10. The
Cou Rating Sum of this layer
These information can reveal the overview of the structural health of a component corresponding to this Com Coh/Cou Digraph, which is useful for preliminary diagnosis, albeit without a 100% guarantee.For instance, the above
Com Coh/Cou Digraph demonstrates a pretty decent system design, because all its information shown is quite good.
On a side note:
If drawing a Com Coh/Cou Digraph for a system's rather difficult, then it can mean that the system itself's incredibly ill-designed.[/spoiler]
Relations Between Com, Coh, InCou And OutCouThe point of combining component diagram, cohesion diagram and coupling digraph into a single Com Coh/Cou Digraph isn't just to show all useful information in 1 shot, but also to demonstrate the relationships between those information.For instance, the below
Com Coh/Cou Digraph illustrates this:
[spoiler]

While it clearly and quickly demonstrates that the system has lots of structural health issues even when it seems to be easy, simple and small, let's still focus on each plugin 1 by 1:
1. Core plugin -
- As it exhibits communicational cohesion, which is generally considered to be a moderate
code smell, the core plugin warrants detailed exploration, whether by using its own
Com Coh/Cou Digraph or not.
- Compared to the total number of features of the whole system, which is 27, and the number of plugins in this system, which is 5, it's likely that the core plugin's still doing a bit too little.
- As the
Coh Rating is a bit high when compared to the number of features, it can indicate that those features themselves are not well-defined enough, like some features overlapping too much with some others, or some features are simply wrapping up too many functionalities.
2. Addon plugin 1 -
- As it doesn't depend on the core plugin but rather another addon plugin, the depth of the system increases from 2 to 3, which complicates the system which is using the
Core Addon Approach(the depth of such system should be always 2). It's because users must also activate another addon plugin in order to use this addon plugin.
- While it exhibits functional cohesion which is ideal, its number of components is also 1, meaning that this addon plugin's probably doing too little.
- As it exhibits content coupling with another plugin, which is generally considered to be 1 of the most destructive
antipatterns, this plugin can break very easily and severely whenever addon plugin 4 changes. This can also lead to bugs that are actually due to this plugin even when they seem to stem from addon plugin 4.
- Combining all the above, it's likely that the entirety of this plugin should really be embedded as parts of addon plugin 4 instead, or the reverse - some features of addon plugin 4 should be placed on addon plugin 1, and the latter should depend on the core plugin instead of the former.
3. Addon plugin 2 -
- As it exhibits logical cohesion, which is generally considered to be a severe
antipattern, it's likely that the features of this plugin doesn't really belong to the same plugin.
- As it only has 2 features while exhibiting logical cohesion, it's likely that the system designer isn't practicing system designs with excellent structural health.
It's because normally the smaller number of components, the easier the cohesion to be higher.- As it exhibits external coupling with another plugin, which is generally considered to be a moderate
antipattern, it can mean that the features are probably not properly grouped or even well-defined, or addon plugin 4's simply an extremely ill-designed and implemented
god object, especially when considering its high number of features, poor
Coh Rating, and the high
InCou Rating Sum.
4. Addon plugin 3 -
- As its number of features are 8 while it exhibits sequential cohesion which is still acceptable, this can either mean that those features are too small or the system's really covering a large number of features that are themselves tightly coupled, which can mean that those features are poorly defined.
- Nevertheless, it's probably the addon plugin with the best structural health.
5. Addon plugin 4 -
- It should be almost certain that this plugin's the one with the worst structural health, because it has the largest number of components which is clearly too large, the worst
Coh Rating, the largest
InCou Rating Sum and
OutCou Rating Sum, and depends on and is depended on the largest number of plugins.
It means that it's the addon plugin that should be dealt with first.- It means that this addon's most likely an extremely ill-designed and implemented
god object, which is already mentioned before.
- Combined with the fact that the core plugin's doing a bit too little, it's probable that some features of addon plugin 4 should belong to the core addon instead.
- Even then, addon plugin 4 will still likely be a
big ball of mud, meaning that some of the rest of the features should be further delegated to some other existing of new addon plugins.
- Considering the fact that this plugin exhibits common coupling, which is generally considered to be a severe
antipattern, with the core plugin, it seems that the this addon plugin affect so much of the system, as if it were the core plugin instead.
- Because of this plugin exhibiting control coupling, which is generally considered to be a severe
code smell, to addon plugin 3, it looks like that the former's attempting to interfere with the latter.
That's far from ideal in the Core Addon Approach, in which every addon plugin should never interfere with any other plugin, and only depend on and the core plugin and nothing else.On a side note:
The OutCou Rating Sum of the core addon should be 0, that of an addon plugin should be 1 or 2, and the InCou Rating Sum of an addon plugin should be 0.[/spoiler]
[/spoiler]
Summary
Component Diagram
[spoiler]
For a layered system, a block diagram can demonstrate the structural overview of a component on a certain layer. When it's the highest layer, the block diagram can demonstrate the structural overview of the entire system. Such diagrams will only expose details on its layer and the one immediately below it, like the number of subcomponents in a component shown by the block diagram.
So as we go from a higher layer to a lower layer, more and more details of a component will be shown, but less and less information about how that component interact with the entire system as a whole will be revealed as well.
In short, this approach ensures the overview shown by a high level block diagram won't be obscured by the details from lower levels, except the one just lower than the current level.
A cohesion diagram can show the Coh Rating, which is a simplified indicator of how high the cohesion is, of a component in a block diagram, and the Coh Rating Sum of the diagram, which is the sum of Coh Rating of all components in the diagram. The lower the Coh Rating and Coh Rating Sum, the higher the cohesion in general.
The overall Coh Rating of the entire system can be different from that derived from diving its Coh Rating Sum by its number of components. Nevertheless, these 2 numbers are extremely unlikely to have a huge difference.
A coupling digraph can show the Cou Rating, which is a simplified indicator of how loose the coupling is, between components in a digraph, and the Cou Rating Sum of the digraph, which is the sum of Cou Rating of all components in the diagram. The lower the Cou Rating and Cou Rating Sum, the looser the coupling in general.
The InCou Rating of a component indicates the coupling from other component to that component; The OutCou Rating of a component indicates the coupling from that component to other components.
The InCou Coupling Sum of a component is the sum of all InCou Rating of that component; The OutCou Coupling Sum of a component is the sum of all OutCou Rating of that component.
In general:
1. The larger the InCou Rating Sum of a component, the easier and more severely that component will be broken due to changes of any other component it's depending on.
2. The larger the OutCou Rating Sum of a component, the easier and more severely that component will break at least some other components depending on it due to it changes.
3. If a component has large InCou Rating Sum and OutCou Rating Sum, when it becomes broken due to changes of some components it depends on, it can in turn break some components depending on it.
For a component having 0 Cou Rating Sum, it means that component doesn't really belong to the system and should become a completely separate plugin that can totally stand on its own.
A Com Coh/Cou Digraph, which is a combination of a component diagram, cohesion diagram and coupling digraph, can reveal the overview of the structural health of its corresponding component, which is useful for preliminary diagnosis, albeit without a 100% guarantee. This is done by quickly showing all the useful information in 1 shot and demonstrating their relationships:
1. The number of subcomponents of each component
2. The total number of subcomponents
3. The Coh Rating of each component
4. The Coh Rating Sum
5. The directed dependencies between components
6. The InCou Rating of each component
7. The OutCou Rating of each component
8. The InCou Rating Sum of each component
9. The OutCou Rating Sum of each component
10. The Cou Rating Sum of this layer
For instance:
1. Normally the smaller number of components, the easier the cohesion to be higher.
2. Components having an exceptionally large/small number of subcomponents, having a poor Coh Rating, InCou Rating or OutCou Rating, or having an extraordinarily large InCou Rating Sum or OutCou Rating Sum, are most likely outstanding troublemakers and should thus be prioritized over those not as problematic.
If drawing a Com Coh/Cou Digraph for a system's rather difficult, then it can mean that the system itself's incredibly ill-designed.
[/spoiler]
That's all for now. As mentioned, I'll use some plugins to demonstrate some practical applications in the subsequent replies.




